Image attribution: Public Domain, <a href=”https://commons.wikimedia.org/w/index.php?curid=481874″>https://commons.wikimedia.org/w/index.php?curid=481874</a>
Here is a “taste” of some of the content I cover related to pattern recognition. By no means is this complete or meant to be a comprehensive overview of how we process patterns.
During the summer before I entered graduate school, I volunteered with other students in my graduate program to work a booth at the state fair. Through this experience I had the pleasure of meeting Tara Fall, a woman who experienced a stroke that caused her to develop prosopagnosia, or face blindness. Tara is wonderfully open about her experience. Faces are special. This is what I’ve learned from her, my neuroscience education, and reading Oliver Sacks’ books.
Imagine walking down the street and seeing someone next to you, following you, only to realize its your own reflection in shop windows.
Imagine not being able to recognize your own children, especially after they get a haircut.
Imagine struggling to distinguish the face of your partner from a stranger.
These are some of the struggles individuals with prosopagnosia struggle with. Prosopagnosia is a neurological condition caused by damage to the fusiform gyrus, or fusiform face area, on the right side of the brain (which is specialized for processing spatial information). This is an area of the brain that runs along the ventral portion of the occipital-temporal lobes.
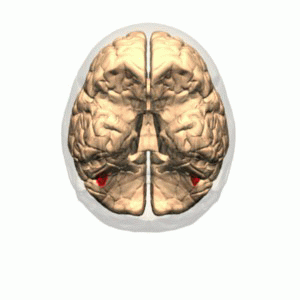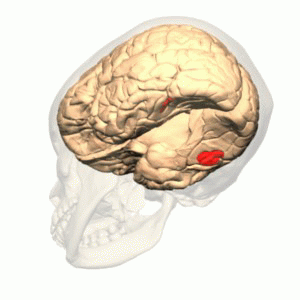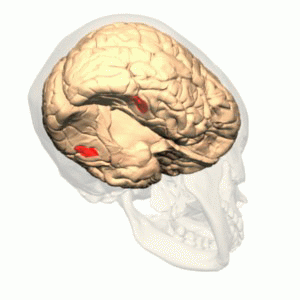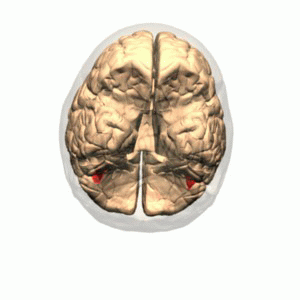
By Polygon data were generated by Database Center for Life Science(DBCLS)[2]. – Polygon data are from BodyParts3D[1]. FFA region is colored based on mid-fusiform sulcus location. (PMC 3962787), CC BY-SA 2.1 jp, https://commons.wikimedia.org/w/index.php?curid=42751712
Faces are one among many patterns we need to perceive and recognize. For example, we perceive and recognize an immense number of objects (chairs, tables, houses…), a large proportion of the population can recognize letters and numbers, and we even recognize patterns when they aren’t necessarily there (i.e., Jesus in toast? – this is called apophenia).
In other words, our brains are excellent at taking sensory information from the environment and converting it into a meaningful perceptual experience. How does this happen? And why are faces special?
Let’s start with “how.” A number of theories have been proposed to describe How we recognize patterns. Three of these theories include Template Theory, Feature Theory, and Structural Theory. Template theory proposes that our brains/minds have a template or snapshot of holistic patterns we encounter and we recognize said patterns by matching the visual copies to one that is stored in our mind. Template theory cannot explain pattern recognition as a whole. First, it doesn’t allow for variations on the stored copy – meaning in order to match a stored template to a pattern they need to be exact replicas. There is no way that our brains can store enough “exact replicas” of each pattern. Instead, we must rely on some sort of process that allows us to “problem solve” and reconstruct patterns from more basic components. For example, we are capable of recognizing patterns that exist in different forms.
Our sensory memory does store templates for a brief period of time. This helps us see a coherent visual stream of information. When we “see” we are actually seeing a series of brief fixations or static images. We are unaware of these brief fixations and instead see the world as continuous because our perceptual system stores the visual information long enough to integrate each fixation. This is similar to how movies are created.
But, again, these brief sensory memories cannot explain how we recognize patterns over time.
Instead, feature and structure theories help explain the infinite number of patterns we recognize and the flexibility of our perceptual system.
Feature theory suggests that individual features in the environment are identified. Structure theories point to the importance of the relationship of these features. Features, in order to be useful, need to be unique, simple, neurologically represented, and processed in parallel.
Early evidence of the neurological representation of features comes from Hubel & Weisel in the 1950s/60s. Hubel and Weisel studied the cat visual cortex and found that individual neurons selectively respond to specific orientations of rectangular bars. For example, this / and this | and this \ “bar” would activate different sets of individual neurons with certain neurons responding most strongly to each orientation. Subsets of these cells became known more specifically as edge detectors. Indeed, the edges of objects and shapes are particularly important to pattern recognition.

obligatory cat pictures
By Alvesgaspar – Top left:File:Cat August 2010-4.jpg by AlvesgasparTop middle:File:Gustav chocolate.jpg by Martin BahmannTop right:File:Orange tabby cat sitting on fallen leaves-Hisashi-01A.jpg by HisashiBottom left:File:Siam lilacpoint.jpg by Martin BahmannBottom middle:File:Felis catus-cat on snow.jpg by Von.grzankaBottom right:File:Sheba1.JPG by Dovenetel, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=17960205
In order for features to be useful we must be able to recognize features in parallel. This means, we can process many features at one time, rather than only one at a time. For example, we not only see the individual lines that compose a letter, but rather we recognize each feature of a letter at once and even further we can recognize the many features that combine to compose a word.
Processing features in parallel also allows us to identify the structural & configural relations between features. Structural theories are expansions on feature theory that elaborate on how structural relations provide additional information about patterns. For example vertices where features meet add an additional layer of information in identifying information. This also allows more flexibility in our visual processing of patterns.
The configural relations between features are particular important for recognizing faces.
Remember how we started out with faces and said they are special?
Now it’s time to think about why. Consider the information conveyed in a face. Face recognition helps us keep track of important people – your boss, your friends, your family. Faces also carry important social information, such as facial expressions that hint at individual’s emotions and help us regulate our own behavior.
In order to effectively recognize faces, we must identify individual facial features such as noses, mouths, eyes, and first order canonical arrangement of these features. This information simply helps us say, hey that’s a face (not a house). To identify specific faces, we also must process the relational information such as the distance between the eyes in order to distinguish between faces. These features and the relational information help us fuse this information into a gestalt.
When faces are inverted it becomes difficult for us to recognize emotional information or even identify the misalignment of individual features. Because we fuse features into a whole, flipping the gestalt of a face disrupts our ability to process and recognize faces. This “face inversion effect” also suggests that faces are special or that we have expertise in recognizing faces.
Another interesting finding regarding expertise in recognizing faces is the cross-race effect. The cross race effect is the finding that we are less adept at recognizing faces of a different race than our own race. Several explanations for this finding exist.
One such explanation is the perceptual expertise hypothesis. This hypothesis suggests we are better at recognizing same race faces because of experience, exposure, and expertise.
Another hypothesis, the feature selection hypothesis, suggests that race is treated as another feature (like a nose or a mouth) and this feature is more salient in cross race face recognition, therefore tuning out other features. In other words, in recognizing cross race faces, individuals may focus on group classification rather than individual face recognition.
Importantly, we may be able to reduce the cross race effect by using education to encourage individuals to focus on individuating feature recognition rather than race. Indeed, research by Levin showed that we can distinguish between cross race faces and the failure to do so results from a feature selection process rather than a perceptual encoding failure. This has important implication for law enforcement training and for eye witness testimony.
One of the semester long themes in my memory & cognition course this semester involves how our cognitive functions have adapted to solve certain problems in the environment. For example, our perceptual system has evolved to recognize important patterns in the environment. To do this efficiently and effectively, our perceptual streams use features and the relationships between features to parallel process visual information and recognize important patterns. A final stage of this processing involves putting together features and relations into a whole. When patterns are disrupted, such as by flipping them upside-down, they become more challenging to recognize.
We also focus on features that are most salient. This can become problematic in some situations. Indeed, many of the adaptations of our cognitive systems have unintended consequences that lead to cognitive biases, errors in perception, or other challenges. For example we are susceptible to visual illusions because of the way our perceptual system interprets features and relationships between features. We also exhibit the cross race effect because we pick out features in the recognition process that are most salient to us.
I think one of the most important things to take away from this is the relationship between our perceptual-cognitive system and social relationships. Our psychological processes are highly intertwined at different levels and each can inform the other.
Indeed, this post does not even cover many important concepts related to pattern recognition or face recognition such as bottom up/top down processing, among other things. As a reminder, this is not meant to be a comprehensive overview of pattern recognition but rather a taste of some of what’s out there.
Some sources:
Memory by Baddeley, Eysenck, and Anderson
Cognition: Theories & Application by Reed
(Additional links provided in text)
